
 Requisitos:
Requisitos:
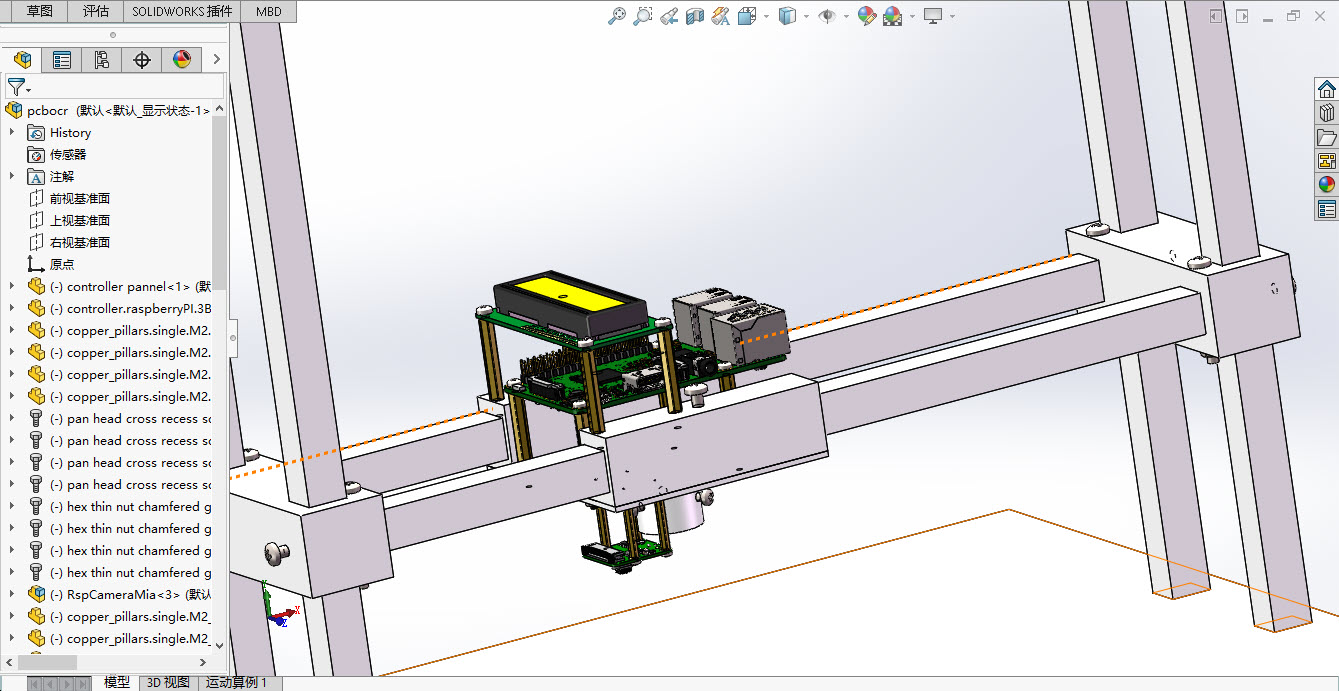
1、识别pcb板上特定的丝印代码 2、丝印代码位置不确定,字体字号均不统一,可确定的是只有大写英文字母和数字 3、pcb板尺寸不超过300mm*300mm 4、通过定义url接口写数据库 5、识别正确率90%以上Diseño estructural: Dado que los tamaños de fuente varían, las fuentes muy pequeñas requieren fotografía macro teleobjetivo, mientras que las grandes requieren fotografía a larga distancia, por lo que la cámara debe variar verticalmente. Para acomodar diferentes tamaños de placas de circuito y serigrafía en distintas ubicaciones, la cámara también debería poder moverse horizontalmente.

Probé el modelo de entrenamiento por defecto, pero la tasa de reconocimiento era baja. Esto puede deberse a que no existe un estándar unificado para la impresión por PCB en escenarios de aplicación, y cada tipo de placa tiene una fuente y un tamaño de fuente serigrafados diferentes. La única solución es entrenar un modelo adecuado para este escenario de aplicación.
Actualizado el 15.6.2020
El preprocesamiento de imágenes de entrada (desenfoque gaussiano - > escala de grises - >binarización) funciona muy bien en el reconocimiento de inglés y numérico, pero la fuente digital (el nombre que le di) es completamente ilegible
Enfoque:
1. Entrenar con fuentes de tubo digital, luego superponer los dos modelos de entrenamiento usando (-l eng+dit)
2. Prueba a entrenar una red neuronal convolucional





