
 Requirements:
Requirements:
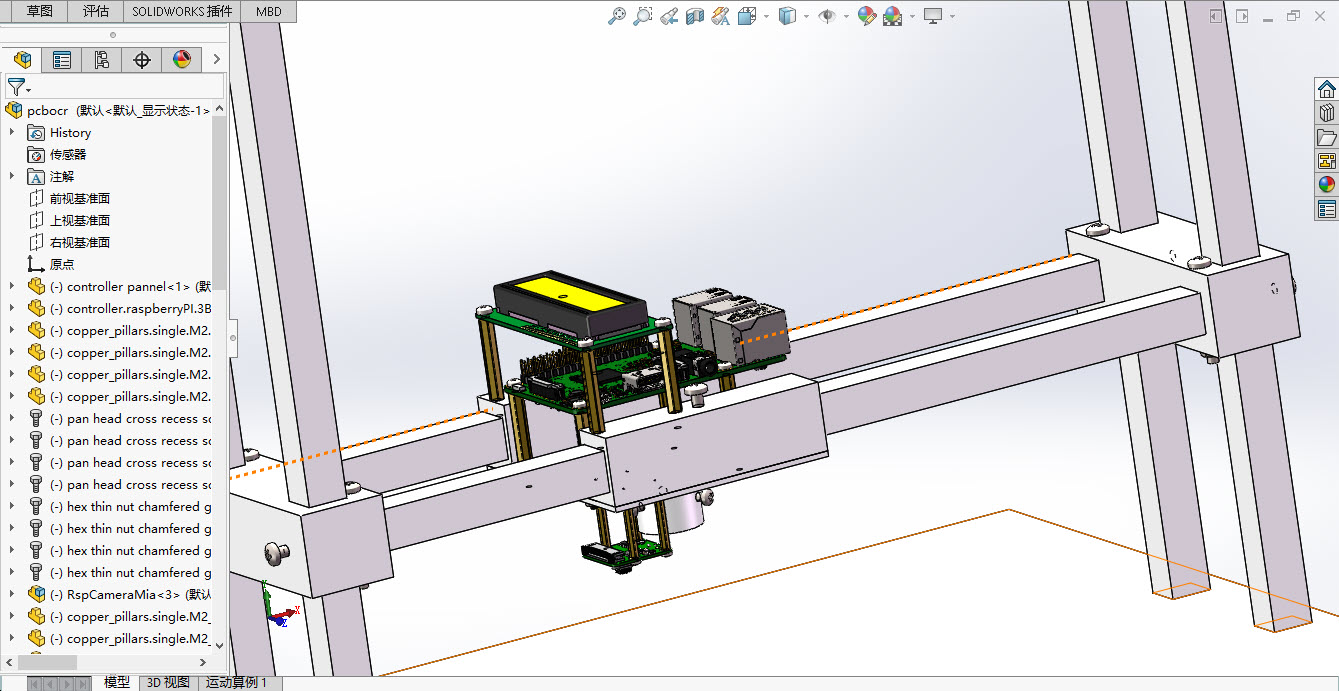
1、识别pcb板上特定的丝印代码 2、丝印代码位置不确定,字体字号均不统一,可确定的是只有大写英文字母和数字 3、pcb板尺寸不超过300mm*300mm 4、通过定义url接口写数据库 5、识别正确率90%以上Structural design: Since font sizes vary, very small fonts require telephoto macro shooting, while large fonts require long-distance shooting, so the camera must vary vertically. To accommodate different sizes of circuit boards and silkscreen code at different locations, the camera should also be able to move horizontally.
Prototype


I tried the default training model, but the recognition rate was low. This might be because there is no unified standard for PCB printing in application scenarios, and each type of circuit board has different silkscreen font and font size. The only solution is to train a model suitable for this application scenario.
Updated on 2020.6.15
Preprocessing input images (Gaussian blur - > grayscale - >binarization) performs very well on English and numeric recognition, but the digital font (the name I gave it) is completely unreadable
Approach:
1. Train on digital tube fonts, then overlay the two training models using (-l eng+dit)
2. Try training a convolutional neural network




2020.11.10. Version update: Completed interface and human-computer interaction using PyQt5



