
 要件:
要件:
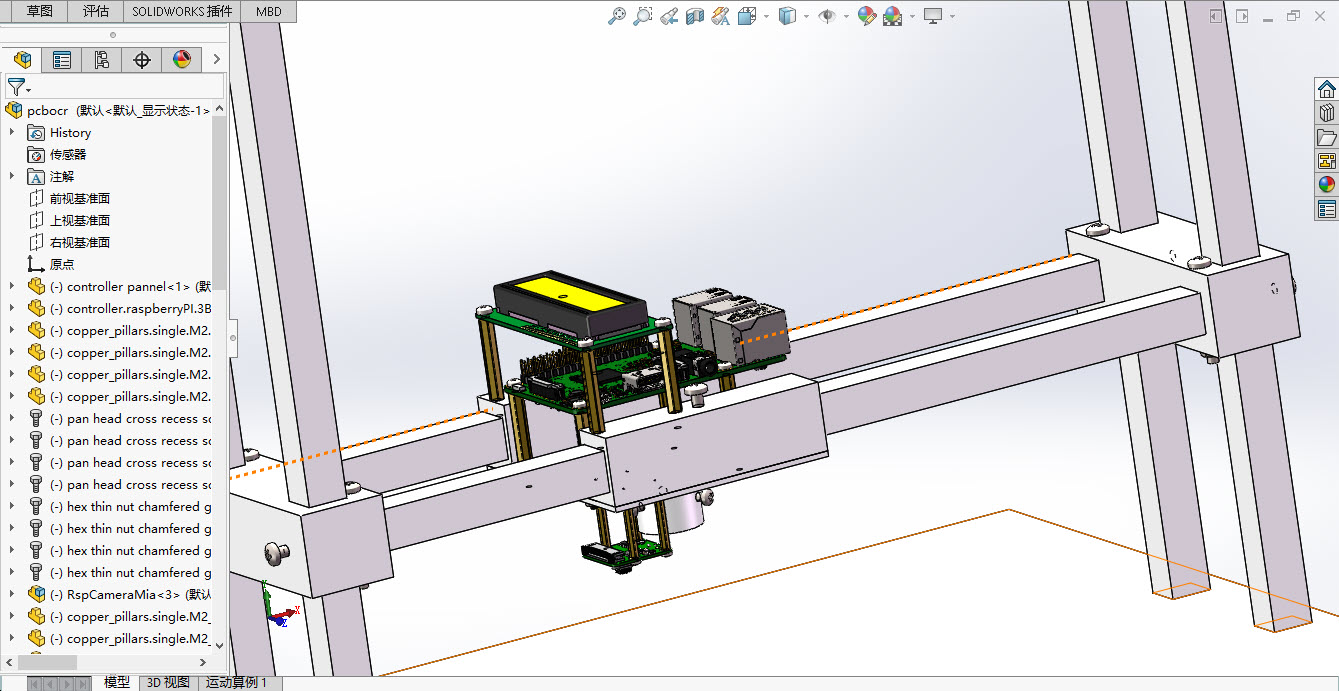
1、识别pcb板上特定的丝印代码 2、丝印代码位置不确定,字体字号均不统一,可确定的是只有大写英文字母和数字 3、pcb板尺寸不超过300mm*300mm 4、通过定义url接口写数据库 5、识别正确率90%以上構造デザイン:フォントサイズが異なるため、非常に小さいフォントは望遠マクロ撮影が必要で、大きなフォントは長距離撮影が必要なため、カメラは縦方向に変化しなければなりません。 異なるサイズの回路基板やシルクスクリーンコードを異なる場所で収容するために、カメラは水平方向にも動くべきです。
試作機


デフォルトのトレーニングモデルを試しましたが、認識率が低かったです。これは、アプリケーションシナリオでのPCB印刷の統一標準が存在せず、基板の種類ごとにシルクスクリーンフォントやフォントサイズが異なるためかもしれません。 唯一の解決策は、この応用シナリオに適したモデルを訓練することです。
2020年6月15日更新
入力画像の前処理(ガウスぼかし - >グレースケール - >バイナリゼーション)は英語と数字認識が非常に良好ですが、デジタルフォント(私が付けた名前)は全く読めません
アプローチ:
1. デジタルチューブフォントでトレーニングし、その後(-l eng+dit)で2つのトレーニングモデルを重ねます
2. 畳み込みニューラルネットワークの訓練を試みる




2020.11.10。バージョン更新:PyQt5を用いたインターフェースおよび人間とコンピュータインタラクションの完了



