
 Exigences :
Exigences :
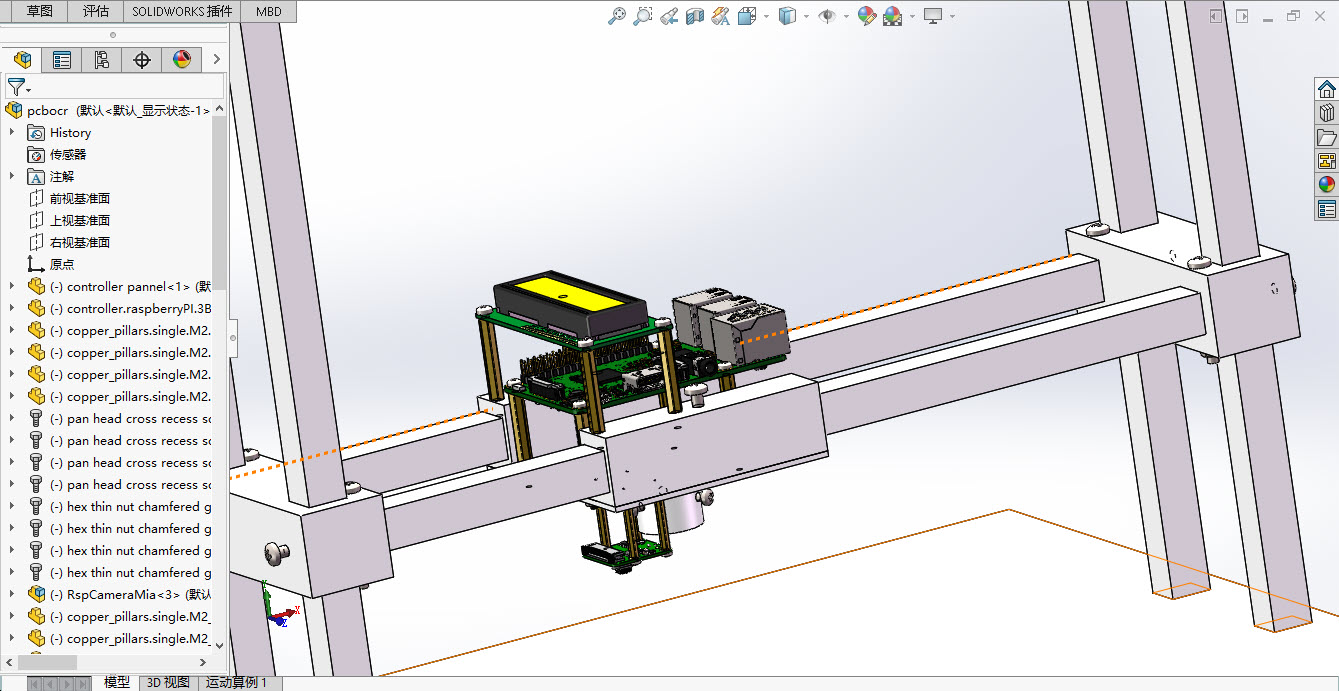
1、识别pcb板上特定的丝印代码 2、丝印代码位置不确定,字体字号均不统一,可确定的是只有大写英文字母和数字 3、pcb板尺寸不超过300mm*300mm 4、通过定义url接口写数据库 5、识别正确率90%以上Conception structurelle : Comme les tailles de police varient, les très petites polices nécessitent un tir macro téléobjectif, tandis que les grandes nécessitent une prise de vue longue distance, donc l’appareil doit varier verticalement. Pour accueillir différentes tailles de circuits imprimés et le code sérigraphié à différents endroits, la caméra devrait également pouvoir se déplacer horizontalement.

J’ai essayé le modèle d’entraînement par défaut, mais le taux de reconnaissance était faible. Cela peut être dû au fait qu’il n’existe pas de norme unifiée pour l’impression PCB dans les scénarios applicatifs, et que chaque type de carte électronique a une police et une taille de police sérigraphiées différentes. La seule solution est d’entraîner un modèle adapté à ce scénario applicatif.
Mis à jour le 15.06.2020
Le prétraitement des images d’entrée (flou gaussienne - > niveaux de gris - >binarisation) fonctionne très bien en anglais et en reconnaissance numérique, mais la police numérique (le nom que je lui ai donné) est totalement illisible
Approche :
1. S’entraîner sur des polices à tube numérique, puis superposer les deux modèles d’entraînement en utilisant (-l eng+dit)
2. Essayez d’entraîner un réseau de neurones convolutionnel





