
 Requisiti:
Requisiti:
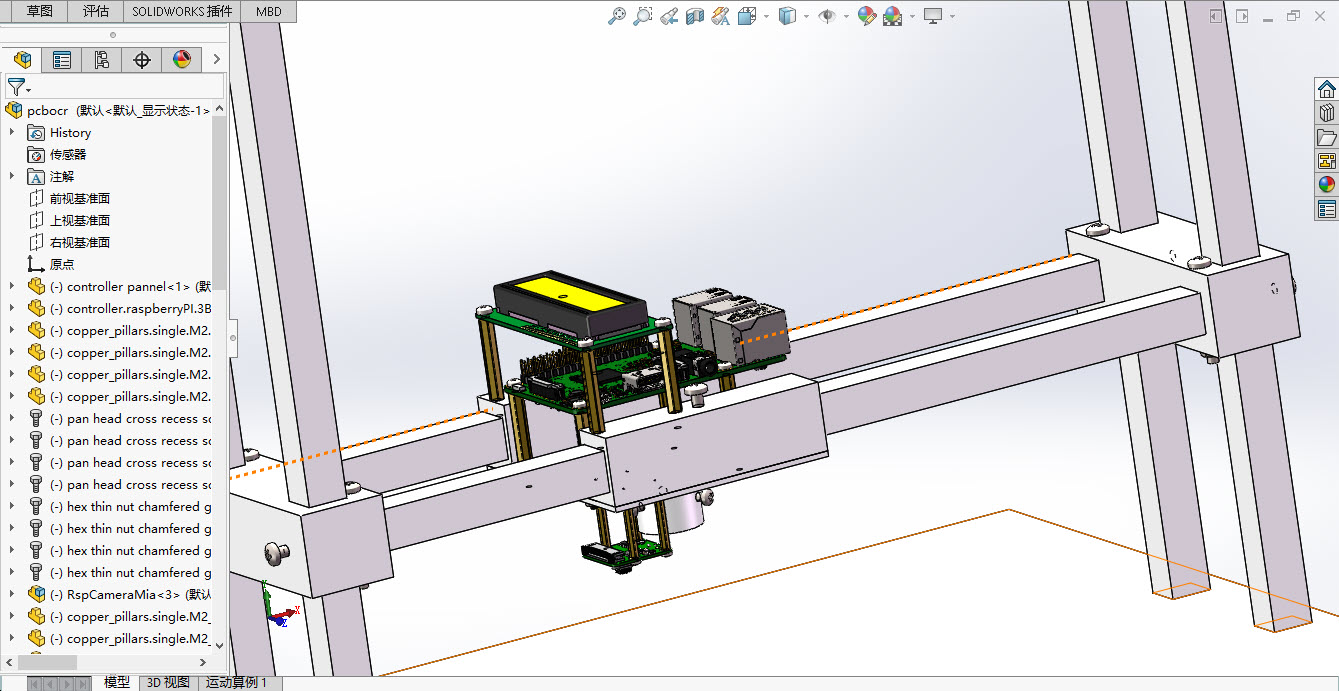
1、识别pcb板上特定的丝印代码 2、丝印代码位置不确定,字体字号均不统一,可确定的是只有大写英文字母和数字 3、pcb板尺寸不超过300mm*300mm 4、通过定义url接口写数据库 5、识别正确率90%以上Progettazione strutturale: Poiché le dimensioni dei font variano, i font molto piccoli richiedono riprese macro teleobjective, mentre i font di grande entità richiedono riprese a lunga distanza, quindi la fotocamera deve variare verticalmente. Per adattarsi a diverse dimensioni di circuiti elettronici e codice serigrafico in posizioni diverse, la telecamera dovrebbe anche essere in grado di muoversi orizzontalmente.

Ho provato il modello di addestramento predefinito, ma il tasso di riconoscimento era basso. Questo potrebbe essere dovuto al fatto che non esiste uno standard unificato per la stampa PCB negli scenari applicativi, e ogni tipo di scheda elettronica ha un font serigrafico e una dimensione di font diversi. L'unica soluzione è addestrare un modello adatto a questo scenario applicativo.
Aggiornato il 15.6.2020
Preprocessing delle immagini di input (sfocatura gaussiana - > scala di grigi - >binarizzazione) funziona molto bene nel riconoscimento in inglese e numerico, ma il font digitale (il nome che gli ho dato) è completamente illeggibile
Approcciamento:
1. Addestrarsi con font digitali a valvole, poi sovrapporre i due modelli di addestramento usando (-l ing+dit)
2. Prova ad addestrare una rete neurale convoluzionale





