
 Anforderungen:
Anforderungen:
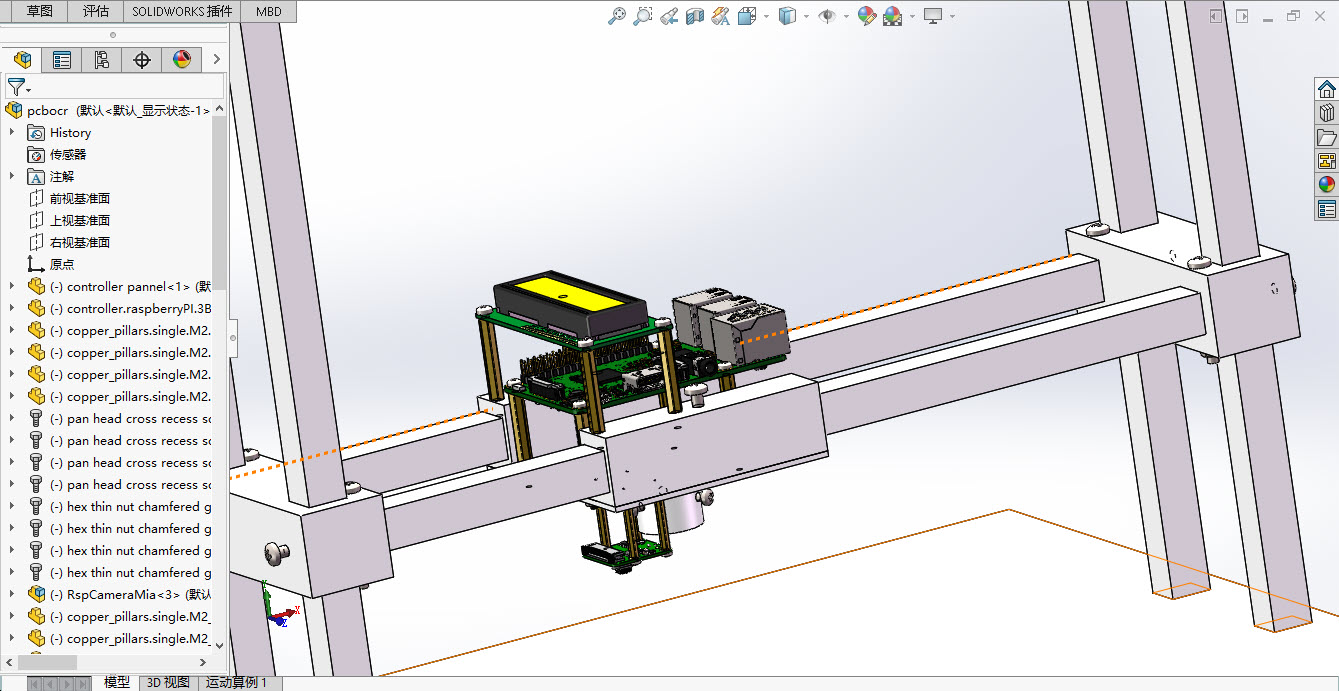
1、识别pcb板上特定的丝印代码 2、丝印代码位置不确定,字体字号均不统一,可确定的是只有大写英文字母和数字 3、pcb板尺寸不超过300mm*300mm 4、通过定义url接口写数据库 5、识别正确率90%以上Strukturelles Design: Da die Schriftgrößen variieren, erfordern sehr kleine Schriften Tele-Makrofotografie, während große Schriften Fernaufnahmen erfordern, sodass die Kamera vertikal variieren muss. Um verschiedene Leiterplattengrößen und Siebdruckcode an unterschiedlichen Orten zu ermöglichen, sollte die Kamera auch horizontal bewegt werden können.

Ich habe das Standard-Trainingsmodell ausprobiert, aber die Erkennungsrate war niedrig. Das könnte daran liegen, dass es keinen einheitlichen Standard für den PCB-Druck in Anwendungsszenarien gibt und jede Leiterplattenart unterschiedliche Siebdruck- und Schriftgröße hat. Die einzige Lösung ist, ein Modell zu trainieren, das für dieses Anwendungsszenario geeignet ist.
Aktualisiert am 15.06.2020
Die Vorverarbeitung von Eingabebildern (Gaußsche Unschärfe – > Graustufen – >Binarisierung) funktioniert sehr gut bei Englisch- und Numerikerkennung, aber die digitale Schriftart (der Name, den ich ihr gegeben habe) ist völlig unlesbar
Ansatz:
1. Trainieren Sie auf digitalen Röhrenschriften und überlagern Sie dann die beiden Trainingsmodelle mit (-l eng+dit)
2. Versuchen Sie, ein konfaltionelles neuronales Netzwerk zu trainieren





